AI検索の構造とは?検索から回答表示までの流れと裏側の技術を解説


「AI検索で上位表示されるには構造化データが必要らしい」 「でも、具体的に何をどう実装すればいいのかわからない」――そんな悩みを抱えていませんか。
2025年現在、検索エンジンの世界は大きな転換期を迎えています。MM総研の調査によると、生成AIの利用用途として最も多いのは「検索機能」 (52.8%)であり、従来のGoogle検索だけでなく、ChatGPTやPerplexityといったAI検索エンジンを情報収集に活用する人が急増しています。
この流れは、地域密着型のビジネスにとって無視できないものとなりました。なぜなら、AI検索エンジンが情報を「引用」する際、Webサイトの情報がどれだけ構造的に整理されているかが大きな判断材料になるからです。
本記事では、AI検索時代において「選ばれるWebサイト」になるための構造設計について、基本的な考え方から具体的な実装方法まで体系的に解説します。MEO対策で累計5,000社以上を支援してきたマケスクの知見をもとに、特に来店型ビジネスを運営する方が今日から実践できる内容をお伝えしていきます。
AI検索時代に「構造」が重要視される理由

なぜ今、Webサイトの「構造」がこれほど注目されているのでしょうか。その背景には、検索エンジンそのものの進化があります。
従来のSEOとAI検索の根本的な違い
従来のGoogle検索は、キーワードの出現頻度や被リンクの数といった「シグナル」をもとに、検索結果の順位を決定していました。上位10件のサイトを一覧表示し、ユーザーは自分でクリックして情報を確認する――というのが基本的な情報収集の流れだったわけです。
一方、AI検索エンジンは異なるアプローチを取ります。ChatGPTやPerplexity、GoogleのAI Overviewは、複数のWebサイトから情報を収集し、それらを統合・要約して一つの回答として提示します。ユーザーはサイトをクリックすることなく、検索結果の画面上で答えを得られるようになりました。
この変化が意味することは明確です。AI検索エンジンに「引用される」ためには、AIが情報を正確に理解し、信頼に足ると判断できるようなサイト設計が不可欠になったということ。そして、その判断において「構造」が極めて重要な役割を果たしているのです。
AIはWebサイトの情報をどう読み解いているのか
人間がWebページを見るとき、私たちは視覚的なレイアウトや文脈から自然と情報の意味を理解できます。「これは店名だな」 「ここに営業時間が書いてあるな」と、直感的に把握できるわけです。
しかし、AIにとってWebページは基本的にHTMLコードの羅列です。見出しなのか本文なのか、住所なのか単なるテキストなのか――その区別をつけるためには、明示的な「意味づけ」が必要になります。
ここで登場するのが構造化データという概念です。構造化データとは、Webページ上の情報に「これは住所です」 「これは営業時間です」 「これはFAQの質問です」といったラベルを付与する仕組みのこと。AIはこのラベルを読み取ることで、ページ内の情報を正確に理解し、適切な文脈で引用できるようになります。
「ゼロクリック検索」時代の到来
AI検索の普及に伴い、「ゼロクリック検索」と呼ばれる現象が顕著になっています。ゼロクリック検索とは、ユーザーが検索結果ページ上で必要な情報を得てしまい、個別のサイトにアクセスしないまま検索を終える行動パターンのことです。
アウンコンサルティングの調査によると、AI Overviewsの利用方法として「AIによる概要を読んだ後、概要内のリンクをクリックしてウェブサイトを確認する」と回答した割合がアメリカとシンガポールで最も多い一方、「AIによる概要の冒頭部分だけを読む」や「もっと見る」をクリックして詳細を読むといった、AI Overviewsのみで完結するゼロクリック検索も一定数存在することが明らかになっています。
この傾向は、WebサイトへのトラフィックがAI検索によって減少する可能性を示唆しています。では、どうすれば自社の情報が「引用元」として選ばれ、ブランド認知やサイト訪問につなげられるのでしょうか。その答えの一つが、適切な構造設計による情報の整理なのです。
AI時代の新しい購買行動モデル「AIMA5」とは
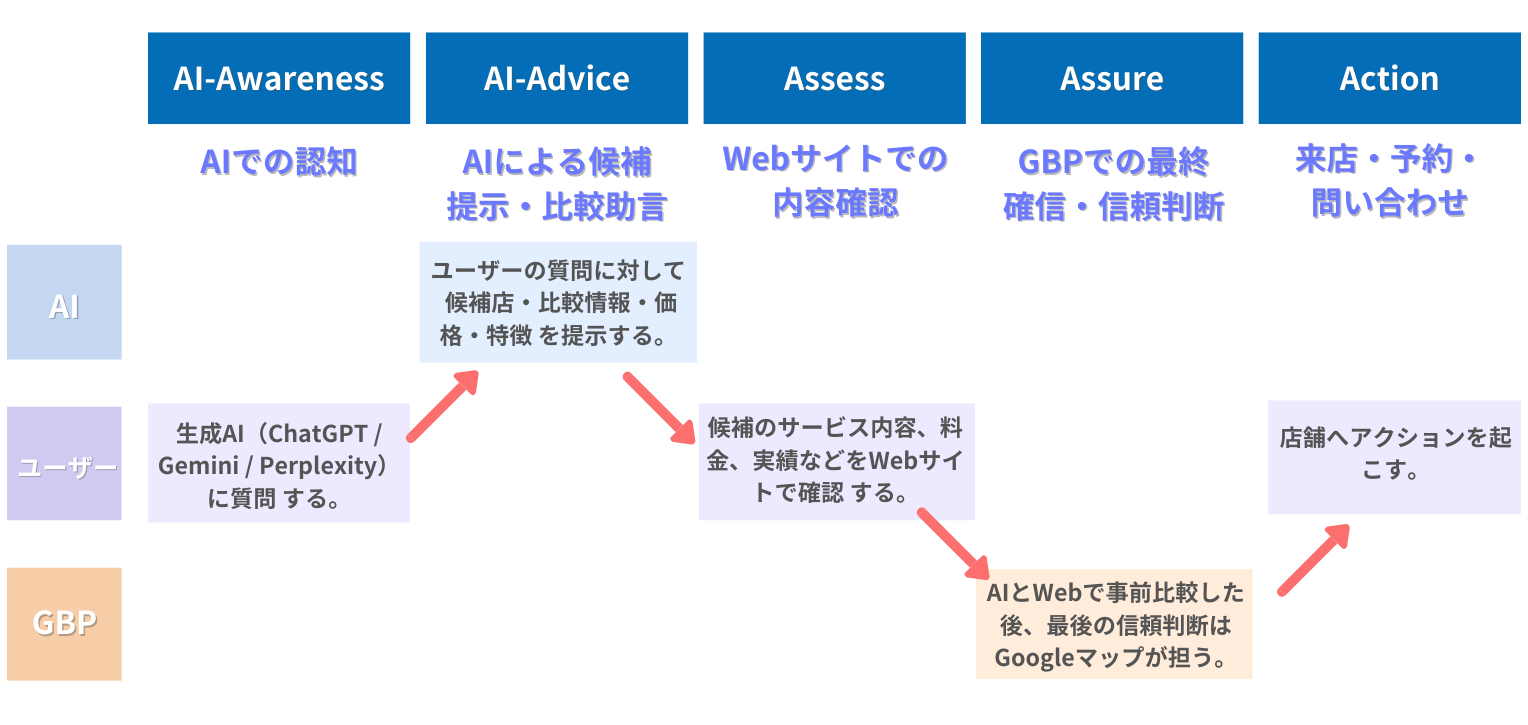
近年、消費者の情報収集方法は大きく変化しています。従来のGoogle検索だけでなく、ChatGPTやGemini、PerplexityなどのAI検索を活用して店舗やサービスを探す人が急増しているのです。
こうしたAI時代の購買行動を体系化したのが「AIMA5 (アイマファイブ)」です。AIMA5は、消費者が店舗を認知してから来店するまでの流れを、以下の5つのステップで整理しています。
- Al-Awareness (Al認知): AI検索で店舗名が表示される
- Al-Advice (AI助言): AIが理由を持っておすすめする
- Assess (Webで深く検討): 公式サイトで詳細を確認する
- Assure (Googleマップで確信): クチコミや写真で最終判断する
- Action(行動): 予約・問い合わせ・来店する
このモデルの特徴は、購買行動の起点が「AI検索」になっている点です。AIに認知され、おすすめされる状態を作ることが、これからの集客において重要な鍵となります。
LLMOは、このAIMA5における最初の2ステップ「Al-Awareness」と「Al-Advice」を強化するための施策です。AI検索で選ばれる店舗になるために、今から準備を始めましょう。
AIMA5の詳細はこちら
構造化データの基礎知識

ここからは、AI検索時代の情報設計において中心的な役割を担う「構造化データ」について、基本的な仕組みから解説していきます。
構造化データとは何か
構造化データとは、Webページ内の情報に対して、検索エンジンやAIが理解できる形式で意味を付与する仕組みです。具体的には、HTMLの中に特定のフォーマットでコードを記述することで、「このテキストは店舗名である」「この数字は価格である」「この文章はQ&Aの回答である」といった意味情報を伝えます。
例えるなら、図書館の蔵書に付けられる分類ラベルのようなもの。本そのものは変わりませんが、ラベルがあることで「これは経済学の本で、棚のこの位置にある」と瞬時に特定できるようになります。構造化データは、Webページという膨大な情報の海の中で、各情報の「居場所」と「役割」を明確にする役割を果たしているわけです。
Schema.orgという共通規格
構造化データを記述する際に使用される共通規格がSchema.orgです。Schema.orgは、Google、Microsoft (Bing)、Yahoo!、Yandexといった主要な検索エンジンが共同で策定した規格で、世界中のWebサイトで広く採用されています。
Schema.orgでは、「Organization」(組織)、「Local Business」 (地域ビジネス)、「Product」(商品)、「FAQPage」 (FAQ)など、さまざまな種類の情報を定義するための「型」(タイプ)が用意されています。この型を使うことで、どのような情報でも検索エンジンが理解できる形式で記述できるようになります。
日本語のWebサイトでも、Schema.orgの規格に従って構造化データを記述すれば、Googleをはじめとする検索エンジンに情報を正確に伝えることが可能です。言語の壁を超えて、グローバルに通用する「情報の共通言語」といえるでしょう。
JSON-LDが推奨される理由
構造化データをWebページに実装する方法(シンタックス)には、主に3つの形式があります。JSON-LD、Microdata、RDFaです。この中で、Googleが公式に推奨しているのがJSON-LD形式です。
JSON-LDが推奨される理由は主に3つあります。
まず、HTMLの構造に影響を与えずに実装できる点。JSON-LDはscriptタグ内に記述するため、既存のHTMLコードを変更する必要がありません。Microdataのように、本文中のタグに属性を追加していく形式と比べると、保守性が格段に向上します。
次に、可読性が高い点。JSON形式は人間にとっても読みやすく、編集や修正が容易です。開発者でなくても、ある程度の構造は理解できるでしょう。
最後に、動的なコンテンツへの対応が柔軟な点。JavaScriptで動的に生成されるコンテンツにも対応しやすく、現代のWebサイト制作との相性が良いといえます。
構造化データとSEO・AI検索の関係
構造化データを実装することで、検索結果に「リッチリザルト」と呼ばれる拡張表示が出現する可能性があります。リッチリザルトとは、通常のタイトルとメタディスクリプションに加えて、星評価、価格、FAQ、画像などの追加情報が検索結果に表示される形式のことです。
リッチリザルトが表示されると、検索結果ページでの視認性が高まり、クリック率の向上が期待できます。ただし、ここで注意したいのは、構造化データ自体は検索順位を直接左右するランキング要因ではないという点です。
Googleは公式に、構造化データがランキングに直接影響するとは述べていません。しかし、間接的な効果は確実に存在します。リッチリザルトによるクリック率向上、AIによる正確な情報理解、そしてユーザー体験の向上―――これらが複合的に作用し、結果としてSEOパフォーマンスの改善につながるケースは少なくありません。
AI検索においては、構造化データの重要性がさらに高まります。AIは構造化データを通じて情報の意味を正確に把握し、信頼性の高い情報源として認識する傾向があるためです。「AI検索に選ばれる」ためには、構造化データによる情報の明確化が欠かせない要素となっています。
来店型ビジネスが優先すべき構造化データ5選

Schema.orgには数百種類のタイプが定義されていますが、すべてを実装する必要はありません。特に来店型ビジネスの場合、優先的に取り組むべき構造化データは限られています。ここでは、飲食店、美容サロン、クリニック、小売店などの地域ビジネスに効果的な5つの構造化データを、優先度順に紹介します。
優先度1: Local Business (地域ビジネス情報)
来店型ビジネスにとって最も重要な構造化データがLocal Businessです。店舗名、住所、電話番号、営業時間、定休日といった基本情報を検索エンジンに正確に伝えることができます。
Local Businessを実装する最大のメリットは、Googleビジネスプロフィールとの情報整合性を担保できる点にあります。Webサイトと Googleマップ上の情報が一致していることは、検索エンジンからの信頼獲得において非常に重要です。NAP情報 (Name、Address、Phone)の一貫性は、ローカルSEOの基本中の基本ですが、構造化データを使うことでより明確にその情報を伝達できます。
Local Businessには、より具体的な業種を指定できるサブタイプも存在します。飲食店であればRestaurant、美容院であればHairSalon、歯科医院であればDentistといった具合です。自社の業種に合ったサブタイプを選択することで、より精度の高い情報提供が可能になります。
▼ Local Businessで指定できる主な項目
- name(店舗名)
- address(住所)
- telephone(電話番号)
- opening Hours Specification(営業時間)
- priceRange(価格帯)
- geo(緯度・経度)
- image(店舗画像URL)
優先度2:FAQPage (よくある質問)
AI検索時代において、FAQPageの重要性は急速に高まっています。その理由は、AIが質問と回答のセットを非常に扱いやすいからです。
ユーザーがAI検索で質問を投げかけたとき、AIは信頼できる情報源から回答を引用します。FAQPageで構造化された質問と回答は、まさにそのニーズに合致した形式で情報が整理されているため、AI Overviewsや各種AI検索エンジンで引用されやすい傾向があります。
FAQPage実装の際のポイントは、ユーザーが実際に持つ疑問をベースに質問を設計することです。「当店について」といった一般的すぎる質問ではなく、「駐車場はありますか?」 「予約なしでも利用できますか?」 「クレジットカードは使えますか?」といった、具体的で実用的な質問を用意しましょう。
Googleの検索結果においても、FAQPageを実装しているページは「よくある質問」としてリッチリザルト表示される可能性があります。検索結果ページでの占有面積が増えるため、クリック率の向上にも寄与します。
優先度3:Organization (組織情報)
Organizationは、企業や組織としての情報を構造化するためのタイプです。Local Businessが個々の店舗情報を扱うのに対し、Organizationは企業全体の情報を定義します。
企業のロゴ、公式SNSアカウント、設立年、代表者名などを構造化することで、Googleのナレッジパネル(検索結果右側に表示される企業情報ボックス)に正確な情報が反映されやすくなります。ブランドの認知度向上と信頼性の訴求に効果的です。
複数店舗を展開している企業の場合、本社サイトにOrganizationを、各店舗ページにLocal Businessを実装するという使い分けが一般的です。この階層構造により、「この店舗はこの企業が運営している」という関係性を検索エンジンに明確に伝えられます。
優先度4:Article / BlogPosting(記事情報)
ブログやコラムを運営している場合、ArticleまたはBlogPostingの構造化データが有効です。記事のタイトル、著者、公開日、更新日、メイン画像などの情報を構造化することで、検索エンジンにコンテンツの詳細を伝えられます。
特に重要なのは著者情報(author)の設定です。「誰が書いた記事なのか」という情報は、E-E-A-T(経験、専門性、権威性、信頼性)の評価において重視される要素の一つ。著者の名前とプロフィールページへのリンクを構造化データに含めることで、コンテンツの信頼性を示すことができます。
また、公開日と更新日を明記することで、情報の鮮度も伝達できます。AI検索は最新の情報を優先的に引用する傾向があるため、記事を更新した際は更新日(dateModified)も必ず反映させましょう。
優先度5: Product/Service (商品・サービス情報)
物販やサービスを提供している事業者は、ProductやServiceの構造化データも検討する価値があります。商品名、価格、在庫状況、評価などを構造化することで、検索結果にリッチスニペットとして表示される可能性が生まれます。
来店型ビジネスの場合、すべての商品を構造化する必要はありません。看板メニューや主力商品に絞って実装するのが現実的です。例えば、飲食店であれば人気メニューを数品、美容サロンであれば代表的な施術プランをいくつか構造化するといったアプローチが効率的でしょう。
AggregateRating (集計された評価)を併せて実装すれば、「★4.5 (ロコミ120件)」のような評価情報も検索結果に表示されます。ただし、架空の評価データを設定することはGoogleのガイドライン違反となるため、実際のロコミデータに基づいた情報のみを使用するよう注意してください。
JSON-LD形式での具体的な実装方法
ここからは、実際にJSON-LD形式で構造化データを実装する方法を解説します。コードの書き方から設置場所、検証方法まで、実務で必要な知識を網羅的にお伝えします。
JSON-LDの基本構造を理解する
JSON-LDは、HTMLのheadタグまたはbodyタグ内にscript type=”application/ld+json”として記述します。基本的な構造は以下の通りです。
まず、@contextで使用する規格 (schema.org)を宣言します。次に、@typeでデータの種類を指定します。その後、各プロパティに具体的な値を設定していくという流れです。
JSON形式では、プロパティ名と値をコロン(:)で区切り、各項目はカンマ(,)で区切ります。最後の項目にはカンマを付けません。文字列は必ずダブルクォーテーション(“)で囲みます。全角文字(日本語)も問題なく使用できますが、半角の記号類には注意が必要です。
Local Businessの実装例
来店型ビジネスにとって最も基本となるLocal Businessの実装例を見てみましょう。飲食店を想定した具体的なコードです。
“引用”
Local Business構造化データでは、@typeに業種を指定し、name、address、telephone、opening Hours Specificationなどの必須項目を記述します。住所はPostalAddress型で構造化し、都道府県、市区町村、番地を個別に指定することで精度の高い位置情報を伝達できます。
引用元:Google検索セントラル
このコードで注目すべきポイントは、住所(address)が入れ子構造になっている点です。Schema.orgでは、住所を単なる文字列ではなく、PostalAddressという型で構造化することを推奨しています。都道府県、市区町村、番地といった要素を個別に指定することで、より正確な位置情報を伝えられます。
営業時間(opening Hours Specification)も同様に、曜日ごとの開店・閉店時間を詳細に設定できます。ランチとディナーで営業時間が異なる場合や、土日だけ営業時間が変わる場合も、複数のOpening Hours Specificationを配列で定義すれば対応可能です。
FAQPageの実装例
次に、AI検索で特に重要となるFAQPageの実装例です。FAQPageでは、mainEntityの中にQuestionとAnswerのペアを配列で格納します。
質問数に制限はありませんが、実際にページ上に表示されている質問と回答だけを構造化するというルールがあります。ページに表示されていない質問を構造化データにだけ記述することは、Googleのガイドライン違反となります。
回答文(text)は、簡潔かつ具体的に記述するのがベストです。AI検索で引用される際に、そのまま回答として表示される可能性があるためです。曖昧な表現を避け、ユーザーが知りたい情報を過不足なく伝えましょう。
複数の構造化データを組み合わせる方法
実際のWebサイトでは、1ページに複数の構造化データを実装するケースが多くあります。例えば、店舗のトップページにLocal BusinessとFAQPage、Organizationを同時に設定するといった具合です。
複数の構造化データを実装する方法は2つあります。一つは、それぞれ独立したscriptタグで記述する方法。もう一つは、@graphを使って一つのscriptタグ内にまとめる方法です。
どちらの方法でも検索エンジンは正しく認識しますが、@graphを使う方法はコードの管理がしやすいというメリットがあります。ただし、構文エラーが発生した場合に全体が無効になるリスクもあるため、十分な検証が必要です。
WordPressでの実装方法
WordPressを利用している場合、構造化データの実装にはいくつかの方法があります。
最も手軽なのはプラグインを利用する方法です。「Yoast SEO」「Rank Math」 「Schema Pro」といったプラグインは、管理画面から必要な情報を入力するだけで構造化データを自動生成してくれます。コーディングの知識がなくても実装できる点が大きなメリットです。
ただし、プラグインによっては生成されるコードが限定的だったり、細かなカスタマイズができなかったりする場合もあります。自社のニーズに合ったプラグインを選定することが重要です。
より細かな制御を行いたい場合は、テーマファイルに直接記述する方法もあります。header.phpやfooter.php、あるいはカスタムフィールドとテンプレートタグを組み合わせて、動的に構造化データを出力できます。開発者のサポートが必要になりますが、柔軟性は格段に高まります。
AI検索で「選ばれる」ためのサイト構造設計

構造化データのマークアップだけでは、AI検索対策は完結しません。サイト全体の情報設計、つまり「どのような構造でコンテンツを配置するか」も同様に重要です。ここでは、AIに評価されるサイト構造の設計指針を解説します。
「意味構造」を意識したサイト設計
AIがWebサイトを評価する際、単にキーワードの有無を見ているわけではありません。サイト全体の情報がどのような関係性で整理されているか――いわゆる「意味構造」を把握しようとしています。
意味構造を明確にするためのポイントは、トピックのカテゴライズと階層化です。例えば、飲食店のサイトであれば「メニュー」 「店舗情報」 「予約」 「ブログ」といった大カテゴリを設定し、その下に関連するページを配置していく。メニューの中でも「ランチ」「ディナー」 「ドリンク」といったサブカテゴリを設けることで、情報の関連性が明確になります。
URL設計もこの階層構造を反映させるのが理想です。/menu/lunch/、/menu/dinner/のように、URLからページの位置づけが分かる設計にすることで、AIだけでなく人間にとっても理解しやすいサイトになります。
内部リンクによる関連性の明示
サイト内のページ同士を内部リンクで結ぶことは、従来のSEOでも重視されてきた施策です。AI検索においても、内部リンクは情報の関連性を示す重要なシグナルとなっています。
効果的な内部リンクのポイントは、関連性の高いページ同士を自然に結ぶこと。例えば、ブログ記事の中で自社サービスについて触れる際に、そのサービスの詳細ページヘリンクを貼る。FAQページから関連するブログ記事へ誘導する。こうした自然な文脈の中でのリンク設置が、AIに対して「これらのページは互いに関連している」というシグナルを送ります。
アンカーテキスト(リンクに設定するテキスト)も重要です。「こちら」 「詳細はこちら」といった曖昧な表現ではなく、リンク先の内容を具体的に示すテキストを使用しましょう。「ランチメニューの詳細」「予約方法について」のように、リンク先で何が得られるかが明確になるようにします。
見出し構造の最適化
HTMLの見出しタグ (h1、h2、h3…)は、ページ内容の階層構造を示す重要な要素です。AIはこの見出し構造を手がかりに、ページのトピックや情報の重要度を判断しています。
見出し構造最適化の基本ルールは、論理的な階層を守ることです。h1の下にh3がいきなり来るような飛ばし方は避け、h1→h2 h3という順序を守ります。また、h1はページ内で1つだけ使用し、そのページの主題を明確に示すものにしましょう。
見出しの内容も重要です。「概要」 「詳細」といった抽象的な表現ではなく、その見出しの下で何について説明しているのかが分かる具体的な表現を使います。「当店の営業時間と定休日について」 「ご予約からご来店までの流れ」のように、見出しだけを読んでも内容が想像できるようにしてください。
BLUF(結論先行)のコンテンツ構成
AI検索に引用されやすいコンテンツには、ある共通点があります。それは、結論が先に述べられているという構成です。
BLUFとは「Bottom Line Up Front」の略で、結論を最初に提示し、その後で詳細や背景を説明するライティング手法です。AIは情報を抽出して要約する際、文章の冒頭部分を重視する傾向があります。結論が後回しになっている文章は、AIにとって「何についての情報なのか」を把握しにくいのです。
実践的には、各セクションの冒頭で「結論」を明示し、その後で「理由」や「詳細」を説明するという流れを意識します。「当店は予約優先制です。週末は特に混雑するため、事前のご予約をおすすめしております。予約方法は~」というように、最も知りたい情報を最初に提示するわけです。
エンティティの明確化
「エンティティ」とは、AIや検索エンジンが認識する「固有の存在」のこと。人物、場所、組織、商品など、他と区別可能な対象を指します。AI検索では、このエンティティの認識精度が検索結果の品質を大きく左右します。
自社のWebサイトで重要なエンティティ(店舗名、ブランド名、代表者名、主力商品名など)を一貫した表記で使用することが、AIによるエンティティ認識を助けます。サイト内で「株式会社○○」と「(株)○○」と「○○社」が混在しているような状態は避けましょう。
また、エンティティに関する情報は、できるだけ主張の近くに配置することも効果的です。「東京都渋谷区で20年以上の実績を持つ○○店では~」のように、店舗名と所在地、実績といった関連情報をまとめて記述することで、AIはそれらの情報が同一のエンティティに紐づいていると認識しやすくなります。
構造化データ実装後の検証と効果測定

構造化データを実装したら、正しく機能しているかの検証と、効果測定が必要です。ここでは、実装の確認方法から継続的な改善サイクルまで解説します。
実装確認に使えるツール
構造化データが正しく記述されているかを確認するためのツールは複数存在します。
Googleリッチリザルトテストは、Googleが提供する公式ツールです。URLを入力すると、そのページの構造化データを解析し、リッチリザルトとして表示可能かどうかを判定してくれます。エラーや警告がある場合は具体的な箇所も示されるため、デバッグに役立ちます。
Schema Markup Validatorは、Schema.org公式の検証ツールです。Googleのツールがリッチリザルト表示の可否を判定するのに対し、こちらはSchema.orgの仕様に準拠しているかどうかを厳密にチェックします。より技術的な検証が必要な場合に有用です。
JSONLintは、JSON形式の構文チェックに特化したツールです。構造化データはJSON形式で記述するため、カンマの付け忘れや括弧の不整合といった構文エラーを発見するのに役立ちます。エラーが出る場合は、まずこのツールで構文をチェックしてみるとよいでしょう。
Google Search Consoleでの効果確認
実装後の効果測定には、Google Search Consoleが最も有効です。「検索パフォーマンス」レポートでは、表示回数、クリック数、CTR(クリック率)、平均掲載順位の推移を確認できます。
構造化データによる直接的な効果を測定するなら、「拡張」メニューを確認しましょう。ここには「FAQ」 「ローカルビジネス」 「パンくずリスト」など、検出された構造化データの種類と、エラーの有無が表示されます。有効なアイテム数が増えていれば、構造化データが正しく認識されている証拠です。
リッチリザルトの表示状況については、「検索パフォーマンス」レポートの「検索での見え方」フィルターで確認できます。「リッチリザルト」や「FAQ」でフィルタリングすることで、リッチリザルト経由の流入データを抽出可能です。
AI検索での引用状況を確認する
AI検索(ChatGPT、Perplexity、GoogleのAI Overviewなど)で自社の情報がどのように扱われているかを確認することも重要です。ただし、AI検索は従来の検索エンジンと異なり、結果を計測するための標準的なツールがまだ存在しません。
現時点で可能なのは、手動でのモニタリングです。自社に関連するキーワードでAI検索を実行し、回答に自社の情報が引用されているか、引用されている場合はどのような文脈で使われているかを確認します。引用元としてリンクが表示されている場合は、その頻度や傾向も記録しておくとよいでしょう。
定期的なモニタリングを続けることで、「この情報は引用されやすい」 「このキーワードでは引用されない」といった傾向が見えてきます。その傾向をもとにコンテンツを調整していくことが、AI検索対策の現実的なアプローチとなります。
継続的な改善サイクルを回す
構造化データの実装は、一度やったら終わりではありません。情報の更新、新サービスの追加、Googleのガイドライン変更など、継続的なメンテナンスが必要です。
推奨する改善サイクルは以下の通りです。
月次で確認すべきこととして、Google Search Consoleでのエラーチェック、リッチリザルト表示状況の確認、CTRの推移確認があります。営業時間や価格といった変動しやすい情報は、実態と構造化データの内容が一致しているかも確認しましょう。
四半期ごとに確認すべきこととして、FAQの内容更新、新しいコンテンツへの構造化データ追加、競合サイトの動向調査があります。検索行動やAI検索のトレンドは日々変化しているため、定期的な見直しが欠かせません。
年次で確認すべきこととして、全体的な構造化データ戦略の見直し、新しいスキーマタイプの導入検討、サイト構造自体の最適化があります。Schema.orgの仕様やGoogleの対応状況も変化するため、最新情報をキャッチアップしておくことが大切です。
よくあるエラーと注意点

構造化データの実装において、初心者が陥りやすいエラーや注意点をまとめます。事前に把握しておくことで、トラブルを未然に防ぐことができるでしょう。
JSON構文エラー
最も多いのは、JSON形式の構文エラーです。カンマの付け忘れ、余計なカンマ、括弧の不整合、ダブルクォーテーションの閉じ忘れなど、わずかなミスで全体が無効になってしまいます。
よくあるパターンとして、配列やオブジェクトの最後の要素にカンマを付けてしまうケースがあります。JSON形式では、最後の要素にはカンマを付けません。
エディタの構文ハイライト機能を活用したり、JSONLintでチェックしたりすることで、こうしたエラーは容易に発見できます。
ページ内容との不一致
構造化データの内容が、実際のページに表示されている内容と異なる場合、Googleのガイドライン違反となります。ページ上に「営業時間 10:00~20:00」と書かれているのに、構造化データでは「09:00~21:00」と記述されていれば、矛盾が生じます。
特に注意が必要なのはFAQページです。構造化データに記述する質問と回答は、必ずそのページ上に表示されていなければなりません。SEO目的で大量のFAQを構造化データにだけ追加し、ページ本体には表示しないという行為は、スパムとみなされる可能性があります。
同様に、架空のロコミ評価やレビュー数を構造化データに設定することも禁止されています。AggregateRatingを使用する場合は、実際に収集したロコミデータに基づく数値のみを使用してください。
必須プロパティの欠落
各スキーマタイプには、必須のプロパティと推奨のプロパティがあります。必須プロパティが欠落していると、構造化データとして認識されなかったり、リッチリザルトが表示されなかったりする原因になります。
例えば、FAQPageの Questionには「name」 (質問文)と「acceptedAnswer」(回答)が必須です。どちらか一方でも欠けていると、そのFAQは無効として扱われます。
実装前に、Google検索セントラルのドキュメントで各スキーマタイプの必須プロパティを確認しておきましょう。推奨プロパティについても、可能な限り設定することでより詳細な情報を伝えられます。
過剰な構造化データの実装
構造化データは多ければ多いほど良いというものではありません。ページの内容と関係のないスキーマタイプを追加したり、同じ情報を重複して構造化したりすることは、かえって逆効果になる可能性があります。
Googleは過剰なマークアップや誤解を招くマークアップに対して、手動対策(ペナルティ)を適用することがあります。検索結果からリッチリザルトが除外されるだけでなく、サイト全体の評価に影響することも考えられます。
実装の原則は「必要十分」です。そのページで本当に伝えるべき情報は何か、ユーザーにとって価値のある情報は何かを見極め、それらに絞って構造化データを設定するのが賢明です。
E-E-A-Tと構造化データの関係
AI検索時代のSEOを語る上で避けて通れないのが、E-E-A-T(経験、専門性、権威性、信頼性)という概念です。構造化データとE-E-A-Tは、密接に関連しています。
E-E-A-Tとは何か
E-E-A-Tは、Googleがコンテンツの品質を評価する際に重視する4つの要素を表しています。Experience(経験)、Expertise (専門性)、Authoritativeness (権威性)、Trustworthiness(信頼性)の頭文字を取ったものです。
従来のE-A-T(専門性、権威性、信頼性)に「Experience (経験)」が追加されたのは2022年12月のこと。実際にその商品を使った経験がある人、そのサービスを利用した経験がある人のコンテンツが、より高く評価されるようになりました。
AI検索においても、E-E-A-Tは重要な評価軸となっています。AIは複数の情報源から回答を生成する際、信頼性の高い情報源を優先的に引用する傾向があります。E-E-A-Tのスコアが高いサイトは、AI検索でも「選ばれやすい」といえるでしょう。
構造化データでE-E-A-Tを示す方法
構造化データは、E-E-A-Tを検索エンジンやAIに明示的に伝える手段として活用できます。
著者情報(Person / Author) を構造化することで、コンテンツの作成者を明確にできます。著者の名前、プロフィールページURL、所属組織、資格などを記述することで、専門性や経験を示すシグナルとなります。
組織情報(Organization) の構造化も有効です。会社の正式名称、設立年、所在地、受賞歴、資格・認証などを記述することで、組織としての権威性と信頼性を伝えられます。
ロコミ・評価 (Review / AggregateRating) の構造化は、第三者からの評価を示す手段です。実際のお客様の声や評価点を構造化することで、信頼性の裏付けとなります。ただし前述の通り、架空のデータを使用することは禁止されているため注意してください。
コンテンツの信頼性を高める工夫
構造化データだけでなく、コンテンツ本体の信頼性を高めることも重要です。以下のポイントを意識しましょう。
情報源を明記する。統計データや調査結果を引用する際は、出典元をリンク付きで明示します。「○○調査によると」のように曖昧な表現ではなく、具体的な調査名とリンクを提示することで、情報の信頼性が高まります。
更新日を明示する。コンテンツの鮮度は信頼性の重要な要素です。公開日だけでなく、最終更新日も明記することで、情報が最新であることを示せます。構造化データでも、datePublishedとdateModifiedを設定しておきましょう。
専門家の監修を入れる。医療、法律、金融などYMYL (Your Money or Your Life) 領域のコンテンツでは、専門家の監修があると信頼性が格段に向上します。監修者の名前と資格を明記し、可能であれば構造化データにも反映させます。
業種別の実装ポイント

ここまで汎用的な構造化データの知識を解説してきましたが、業種によって重視すべきポイントは異なります。来店型ビジネスの代表的な業種について、実装のポイントを整理します。
飲食店の場合
飲食店にとって最も重要なのは、Restaurantスキーマの実装です。Local BusinessのサブタイプであるRestaurantを使用することで、料理ジャンル、価格帯、予約可否などの飲食店固有の情報を構造化できます。
メニュー情報はMenuスキーマで構造化できます。メニューカテゴリ、各料理の名前、説明、価格などを記述することで、「○○エリアランチ」といった検索で詳細情報が表示される可能性が生まれます。
予約システムを導入している場合は、reservationsプロパティでオンライン予約のURLを設定できます。Googleの検索結果から直接予約ページへ誘導できるため、コンバージョン向上に直結します。
美容サロンの場合
美容サロン(美容院、ネイルサロン、エステなど)は、Health And Beauty BusinessまたはHairSalon、NailSalonといった具体的なサブタイプを使用します。
サービスメニューはServiceスキーマで構造化できます。施術名、所要時間、価格、対象部位などを記述することで、「○○エリア ヘッドスパ 価格」といった検索意図に応えられます。
美容サロンではスタッフ情報の構造化も効果的です。Personスキーマを使って、スタイリストの名前、経歴、得意な施術などを構造化することで、指名検索にも対応できます。
クリニック・医療機関の場合
医療機関はMedical Businessまたは具体的なサブタイプ (Dentist、Physician、 Hospital など)を使用します。医療はYMYL領域に該当するため、E-E-A-Tの観点から特に信頼性の高い情報提供が求められます。
医師・スタッフの資格情報を構造化することが特に重要です。医師免許、専門医資格、所属学会などの情報をPersonスキーマで明示することで、専門性と権威性を示せます。
診療科目や対応可能な症状については、Medical Specialtyプロパティを活用できます。取り扱っている診療内容を漏れなく構造化しておきましょう。
小売店・物販の場合
小売店はStoreスキーマをベースに、取扱商品のカテゴリを示します。ECサイトを併設している場合は、Product スキーマの実装も検討すべきです。
商品ページにProductスキーマを実装することで、商品名、価格、在庫状況、評価などが検索結果に表示される可能性があります。
Offerスキーマを使えば、セール情報や特別価格も構造化できます。購買意欲の高い検索に対応できるため、販促施策との連動を検討してみてください。
MEO対策と構造化データの連携
来店型ビジネスにとって、MEO (Googleマップ最適化)対策は集客の要です。構造化データとMEO対策を連携させることで、より効果的なローカル検索対策が実現できます。
Googleビジネスプロフィールとの情報一致
構造化データとMEO対策を連携させる上で最も重要なのは、情報の一致です。WebサイトのLocal Business構造化データと、Googleビジネスプロフィールに登録されている情報は、完全に一致している必要があります。
店舗名、住所、電話番号(NAP情報)が一致していることは基本中の基本です。営業時間、定休日、価格帯なども、両者で矛盾がないようにしましょう。情報に食い違いがあると、検索エンジンはどちらの情報が正しいのか判断できず、信頼性評価が下がる可能性があります。
また、Googleビジネスプロフィールで設定しているカテゴリと、構造化データの@typeも整合性を取ることが望ましいでしょう。
口コミ情報の活用
Googleビジネスプロフィールに寄せられた口コミは、ローカル検索のランキング要因として重要です。WebサイトでもAggregateRatingを使って評価情報を構造化することで、複数のチャネルから信頼性を示すことができます。
ただし、Googleは、Review構造化データについて「ページ上に表示されているレビューに基づくこと」を求めています。Googleビジネスプロフィールの評価をWebサイトにも掲載し、それをもとに構造化データを設定するという形が正当なアプローチです。
ローカルSEOの総合的な強化
構造化データの実装は、MEO対策の一部として位置づけるのが効果的です。Googleビジネスプロフィールの最適化、サイテーション(他サイトでの店舗情報掲載)の整備、ロコミ獲得施策、そして構造化データの実装――これらを総合的に進めることで、ローカル検索での上位表示とAI検索での引用獲得の両方を目指せます。
マケスクでは、MEO対策を中心としたローカル集客支援において、構造化データの実装も含めた総合的なアドバイスを行っています。累計5,000社以上の支援実績から得られた知見をもとに、業種や規模に応じた最適なアプローチをご提案しています。
今後のAI検索と構造化データの展望
AI検索は日々進化を続けており、構造化データの重要性も変化していく可能性があります。現時点で見えている傾向と、今後への備えについて解説します。
AI検索エンジンの動向
サイバーエージェントGEOラボの調査によると、10代ではChatGPTの検索行動における利用率 (42.9%)がYahoo! JAPAN (31.7%)を上回っており、若年層を中心にAI検索の普及が加速しています。検索エンジンの代替として一度でも生成AIを利用したユーザーの7割が継続利用しているというデータもあり、AI検索は一過性のブームではなく、定着しつつある行動変化といえます。
一方で、博報堂メディア環境研究所の調査では、AI検索の利用率は26.7%となっており、検索エンジン(9割以上)と比べるとまだ差があります。当面は従来のSEO対策とAI検索対策の両立が求められる状況が続くでしょう。
構造化データの今後
構造化データがAI検索の評価においてどの程度重視されているかは、各AI検索エンジンがブラックボックスであるため、明確には分かりません。ただし、構造化データによって情報を整理することは、従来のSEO、AI検索対策、そしてユーザー体験の向上いずれにもプラスに働く施策です。
Googleは構造化データの活用をさらに進める方向性を示しており、AI Overviewsでのリンク表示にも構造化データが影響している可能性が指摘されています。今後、AIが情報を理解するための「共通言語」として、構造化データの役割はますます重要になると考えられます。
今から準備しておくべきこと
AI検索時代を見据えて、今から取り組んでおくべきことを整理します。
基本的な構造化データの実装。Local Business、FAQPage、Organization、 Article――まずはこれらの基本的なスキーマタイプから着手しましょう。完璧を目指す必要はなく、段階的に拡充していくアプローチで構いません。
サイト構造の見直し。情報の階層化、内部リンクの最適化、見出し構造の整理など、サイト全体の意味構造を明確にする取り組みを進めましょう。
E-E-A-Tの強化。著者情報の明示、情報源の明記、専門性の訴求など、コンテンツの信頼性を高める施策に継続的に取り組みましょう。
モニタリング体制の構築。Google Search Consoleでの定期チェック、AI検索での引用状況の確認、競合動向の把握など、継続的なモニタリング体制を整えておくことが大切です。
AI検索時代の構造設計はマケスクにご相談ください
ここまで、AI検索時代における構造化データとサイト構造設計について詳しく解説してきました。要点を改めて整理しましょう。
AI検索の普及により、WebサイトがAIに「選ばれる」ための情報設計がこれまで以上に重要になっています。構造化データは、AIや検索エンジンに情報の意味を正確に伝える手段として、その中核を担う技術です。
来店型ビジネスであれば、Local Business、FAQPage、Organization、Articleといった基本的な構造化データから取り組むのが効果的です。併せて、サイト全体の意味構造の明確化、E-E-A-Tの強化、MEO対策との連携を進めることで、総合的なローカル集客力の向上が期待できます。
とはいえ、構造化データの実装には技術的な知識が必要であり、自社だけで対応するのが難しいケースも多いでしょう。また、実装後の効果測定や継続的な改善も含めると、かなりの労力が必要となります。
マケスクを運営する株式会社トリニアスでは、2017年からMEO対策を中心としたローカル集客支援を行っており、累計5,000社以上の店舗・企業様をサポートしてきました。上位表示達成率96.2%という実績のもと、構造化データの実装を含むWebサイト最適化のご相談にも対応しています。
「構造化データを導入したいが、何から始めればいいか分からない」 「AI検索への対応について相談したい」 「MEO対策と合わせてWeb集客を強化したい」――そのようなお悩みをお持ちであれば、ぜひお気軽にお問い合わせください。
地域ビジネスの「今すぐ使えるWeb集客ノウハウ」を発信するマケスクでは、本記事のようなAI検索・SEO対策に関する最新情報も随時更新しています。ぜひ今後の記事もご覧いただき、自社の集客力強化にお役立てください。
よくある質問
Q. 構造化データを実装すると検索順位は上がりますか?
A. 構造化データは検索順位を直接左右するランキング要因ではありません。ただし、リッチリザルト表示によるクリック率向上、検索エンジンによるコンテンツ理解の促進、AI検索での引用獲得など、間接的にSEOパフォーマンスを向上させる効果が期待できます。
Q. 構造化データの実装に専門知識は必要ですか?
A. JSON-LDの基本的な書き方を理解していれば、シンプルな構造化データは自分でも実装可能です。WordPressを使用している場合は、Yoast SEOやRank Mathなどのプラグインを使えば、コーディング知識がなくても実装できます。ただし、複雑な構造化データや大規模な実装の場合は、専門家のサポートを受けることをおすすめします。
Q. すべてのページに構造化データを入れる必要がありますか?
A. すべてのページに実装する必要はありません。トップページ、店舗情報ページ、サービスページ、よくある質問ページなど、重要なページから優先的に対応するのが現実的です。ブログ記事についても、すべてではなく主力コンテンツに絞って実装するアプローチが効率的でしょう。
Q. 構造化データを実装したらリッチリザルトは必ず表示されますか?
A. 構造化データを正しく実装していても、リッチリザルトが必ず表示されるとは限りません。Googleのアルゴリズムによって表示の可否が判断されるため、実装は表示の「可能性を高める」施策と捉えてください。ただし、構造化データがなければリッチリザルトは表示されないため、実装することで機会損失を防げます。
Q. AI検索対策として構造化データ以外にやるべきことはありますか?
A. 構造化データはAI検索対策の一部です。結論を先に述べるBLUF形式のライティング、FAQコンテンツの充実、E-E-A-T(経験・専門性・権威性・信頼性)の強化、サイト全体の意味構造の明確化なども重要な施策となります。従来のSEO対策を基盤としつつ、AI検索の特性を意識した情報設計を心がけましょう。
MEO対策・ビジネスプロフィール・ストリートビュー
Instagram・LINE・HP/LP制作に関しては、
当メディアの運営会社 株式会社トリニアスにご相談ください。

AI戦略 関連記事
- ChatGPT検索とは?仕組みと従来のGoogle検索との違いをわかりやすく解説
- AI検索の文章の書き方とは?回答に引用されやすい表現と構成のコツ
- AI検索の独自性評価とは?オリジナルコンテンツが重要視される理由
- AI検索で長文が有利な理由とは?ボリューム記事が評価される仕組み
- AI検索の体系的記事とは?情報を整理して引用されやすくする書き方
- AI検索の専門性評価とは?エキスパートとして認識されるための条件
- AI検索の信頼性評価とは?情報源として信頼されるサイトの作り方
- AI検索の情報密度とは?引用されるために必要な内容の濃さと書き方
- AI検索の情報更新とは?鮮度を保って評価され続けるための更新頻度
- AI検索の自社名表示とは?企業名が回答に出るようにする対策と条件
