LLMOのコンテンツ要件とは?AI検索で引用されるために必要な条件


「検索からの流入が減っている」 「ChatGPTやGeminiで自社が全く出てこない」――そんな声が、マーケティング担当者の間で急速に増えています。
2025年に入り、検索体験は大きな転換点を迎えました。ユーザーはもはやキーワードを打ち込んで10本の青いリンクから選ぶのではなく、生成AIに自然な言葉で質問し、要約された回答をそのまま受け取る時代になったのです。
Pew Research Centerの調査によれば、GoogleのAI Overviewが表示された検索ではクリック率が約15%から8%に半減しています。さらにSEMRUSHの大規模調査では、検索全体の約60%が「ゼロクリック検索」――つまりサイトを訪問せずに終わる検索――――であることが明らかになりました。
このような状況で注目を集めているのがLLMO (Large Language Model Optimization)です。そして、AIに「選ばれる」コンテンツを作るためには、従来のSEOとは異なる視点での要件理解が不可欠になっています。
本記事では、LLMOにおけるコンテンツ要件の本質と、実際に引用・参照されるコンテンツを作るための具体的な条件を解説します。
LLMOコンテンツ要件とは何か

LLMOコンテンツ要件とは、ChatGPT、Google Gemini、Perplexityなどの生成AIがコンテンツを「引用・参照に値する」と判断するために満たすべき条件のことを指します。
従来のSEOでは、キーワードの配置やリンク構造、技術的な最適化が中心でした。対してLLMOでは、AIがコンテンツの「意味」を理解し、ユーザーの質問に対する回答として適切かどうかを判断します。この判断基準を満たすための条件こそがLLMOコンテンツ要件なのです。
SEOコンテンツとの決定的な違い
SEOとLLMOの最大の違いは「評価の主体」にあります。
SEOでは検索エンジンのアルゴリズムがコンテンツを「ランキング」し、上位に表示されたものをユーザーが選択します。一方、LLMOではAI自身がコンテンツを「選別」し、その内容を要約・再構成してユーザーに提示するのです。
この違いが何を意味するかというと、検索1位を獲得しても、AIに引用されなければ存在しないのと同じという状況が生まれるということ。逆に、検索順位が低くてもAIが「信頼できる情報源」と判断すれば、回答の根拠として採用される可能性があります。
特に注目すべきは、SE Rankingの調査結果です。GoogleのAIモードで引用されたURLと通常のオーガニック検索トップ10との重複率は、URLレベルでわずか14%、ドメインレベルでも21.9%にすぎませんでした。AIは既存の検索順位とは異なる基準でコンテンツを選んでいることが明確に示されています。
なぜ今コンテンツ要件の理解が必要なのか
生成AIの利用は急速に拡大しています。サイトエンジンの分析によれば、米国ではAIツールのヘビーユーザー(月10回以上利用)の割合が2023年1月の3%から2025年6月には21%へと急増しました。
同時に、AI経由のWebサイトトラフィックは2024年1月から2025年6月までに1,367%増加しています。まだ全体の1%未満とはいえ、成長速度は驚異的であり、このトレンドが続けば6~10年後には従来の検索エンジンに匹敵する規模になる可能性があるとされています。
さらに興味深いのは、AI経由の流入は従来のオーガニック流入と比較して成約率が23%高いという調査結果です。単なる流入数だけでなく、ビジネス成果への影響も大きいことがわかります。
このような背景から、LLMOコンテンツ要件を正しく理解し、AIに選ばれるコンテンツを設計することは、もはや「将来への備え」ではなく「現在の競争力」に直結する課題となっています。
AI時代の新しい購買行動モデル「AIMA5」とは
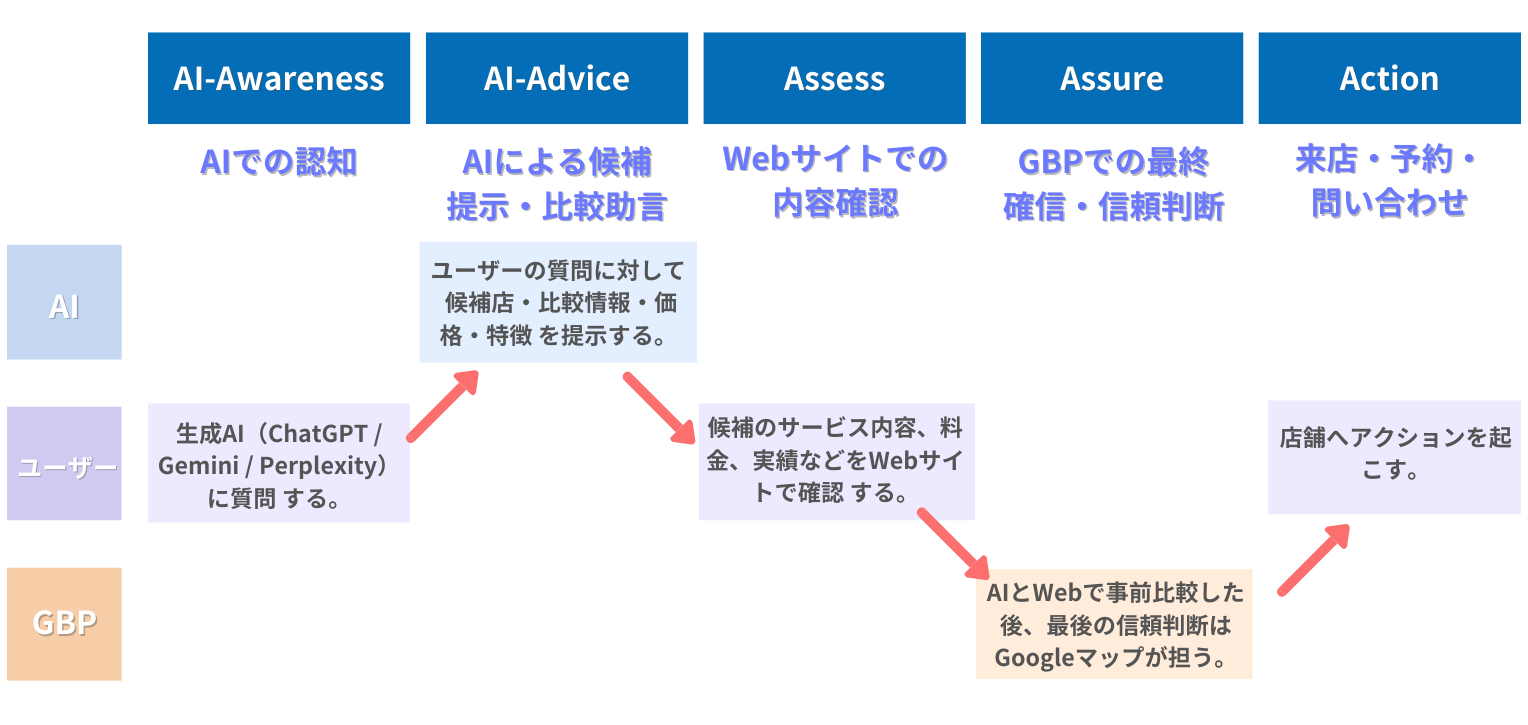
近年、消費者の情報収集方法は大きく変化しています。従来のGoogle検索だけでなく、ChatGPTやGemini、PerplexityなどのAI検索を活用して店舗やサービスを探す人が急増しているのです。
こうしたAI時代の購買行動を体系化したのが「AIMA5 (アイマファイブ)」です。AIMA5は、消費者が店舗を認知してから来店するまでの流れを、以下の5つのステップで整理しています。
- AI-Awareness (AI認知): AI検索で店舗名が表示される
- AI-Advice (AI助言): AIが理由を持っておすすめする
- Assess (Webで深く検討): 公式サイトで詳細を確認する
- Assure (Googleマップで確信): クチコミや写真で最終判断する
- Action(行動): 予約・問い合わせ・来店する
このモデルの特徴は、購買行動の起点が「AI検索」になっている点です。AIに認知され、おすすめされる状態を作ることが、これからの集客において重要な鍵となります。
LLMOは、このAIMA5における最初の2ステップ「AI-Awareness」と「AI-Advice」を強化するための施策です。AI検索で選ばれる店舗になるために、今から準備を始めましょう。
> AIMA5の詳細はこちら
AIが引用するコンテンツに共通する5つの要件

生成AIがコンテンツを引用・参照する際には、明確なパターンが存在します。各種の研究や実践から見えてきた、AIに選ばれるコンテンツの共通要件を解説します。
要件1:情報の出所が明確であること
AIが最も重視するのは「誰が、どのような立場で、どのような根拠をもって発信しているか」という点です。
これは単に著者名を記載すればよいという話ではありません。その著者がなぜその情報を発信する資格があるのか、どのような経験や専門性に基づいているのかが、コンテンツ内で明示されている必要があります。
具体的には以下のような要素が重要になります。
▼情報の出所を明確にする要素
- 著者の専門資格・実績(例:○○業界で15年の経験、△△資格保有)
- 監修者がいる場合はその専門性の明示
- 運営組織の情報(企業概要、設立年数、事業実績)
- 引用データの出典元(政府統計、学術論文、業界団体の調査など)
AIは「引用しても安全かどうか」を判断しています。出所不明の情報をユーザーへの回答に使用することは、AI自身の信頼性を損なうリスクがあるため、徹底的に避けられる傾向にあります。
要件2:質問に対する直接的な回答があること
生成AIは「ユーザーの質問に対する回答を生成する」という目的で動作しています。そのため、質問に対して明確かつ直接的に答えているコンテンツが優先的に引用されます。
ここで重要なのは「結論ファースト」の構造です。導入で長々と背景を説明してから結論を示すのではなく、まず結論を述べ、その後に詳細な説明を加える形式が効果的とされています。
実務的には、見出しで問いを設定し、その直後の段落で端的に答えるQ&A形式が有効です。たとえば「LLMOとは?」という見出しに対して「LLMOとは、生成AIに自社コンテンツが引用されるよう最適化する施策です」と明確に定義を示す形です。
曖昧な表現や回りくどい説明は、AIにとって「答えを抽出しにくい」 コンテンツと判断される要因になります。
要件3:情報が構造化されていること
AIがコンテンツを理解する際、HTMLの構造やマークアップは極めて重要な手がかりとなります。
見出しタグ(H1~H6) を使って論理的な階層構造を作ること、リストや表を適切に使用すること、そしてschema.orgに基づく構造化データを実装することで、AIはコンテンツの「何が重要で、何がどこに書かれているか」を正確に把握できるようになります。
特にLLMO対策で重要とされる構造化データには、以下のようなものがあります。
| スキーマタイプ | 用途 |
| FAQPage | よくある質問と回答のペアを明示 |
| HowTo | 手順やステップを示すコンテンツ |
| Article | 記事の著者、公開日、更新日を明示 |
| Organization | 運営企業・組織の情報 |
| Person | 著者・監修者の専門性や実績 |
構造化データは人間の目には見えませんが、AIにとっては「このサイトは情報を整理して提供しようとしている」というシグナルになります。実装していないサイトと比較して、引用される確率に差が出ることは各種調査で示されています。
要件4:網羅性と深度のバランスが取れていること
AIはユーザーの質問に対して「十分な情報を提供できるか」を判断します。表面的な説明だけのコンテンツより、テーマを深掘りし、関連する疑問にも答えられるコンテンツが好まれます。
ただし、単に文字数を増やせばよいわけではありません。重要なのは「関連するサブトピックを適切にカバーしているか」という点です。
たとえばLLMOについて解説する場合、定義だけでなく「SEOとの違い」 「具体的な対策方法」「効果測定の手法」 「注意点やリスク」といった、読者が次に知りたくなる情報を網羅的に扱うことで、AIが「このコンテンツを参照すれば質問に包括的に答えられる」と判断する可能性が高まります。
これはGoogleのGeminiで使用されている「クエリファンアウト」という仕組みにも関係しています。AIはユーザーの質問を複数のサブトピックに分解し、それぞれに対して情報を収集します。一つのコンテンツが複数のサブトピックに対応していれば、引用される機会が増えることになるのです。
要件5:情報の鮮度が担保されていること
AIは回答の正確性を重視するため、古い情報よりも新しい情報を優先する傾向があります。
特に変化の激しい分野(法規制、テクノロジー、市場動向など)では、コンテンツの更新日が明示されていることが重要です。「2023年の情報に基づく」と明記されたコンテンツより、「2025年12月時点の最新情報」と示されたコンテンツのほうが、AIにとって引用しやすいことは明らかでしょう。
定期的なコンテンツ更新と、更新日の明示(構造化データでのdateModifiedプロパティの実装)は、LLMO対策における基本要件といえます。
E-E-A-TがLLMOコンテンツ要件の土台になる理由

GoogleのE-E-A-T (Experience Expertise Authoritativeness. Trustworthiness)は、従来SEOの評価指標として知られてきました。しかしLLMOの文脈では、これが単なる評価指標ではなく「AIに引用されるための前提条件」として機能しています。
Experienceの示し方
「経験」を示すとは、理論的な知識だけでなく実際の体験に基づいた情報を提供することを意味します。
AIは客観的な情報を好む一方で、実体験に基づく具体的な知見を価値あるものとして認識します。たとえば「一般的にはこうすべきとされている」という説明より、「私たちが実際に100社のクライアントで検証した結果、この方法が最も効果的だった」という情報のほうが、AIにとって引用価値が高くなります。
経験を示す際のポイントは、単なる主観ではなく「検証可能な具体性」を伴うことです。数値データ、期間、対象範囲などを明示することで、経験の信頼性が担保されます。
Expertiseの証明方法
専門性を証明するためには、表面的な説明を超えた深い知見を示す必要があります。
誰でも調べればわかる基本情報の羅列ではなく、その分野の専門家だからこそ指摘できる「見落としがちな点」 「よくある誤解」 「業界の暗黙知」などを含めることで、コンテンツの専門性が際立ちます。
また、著者情報の充実も重要な要素です。記事の末尾に著者プロフィールを記載するだけでなく、Personスキーマで構造化データとしてマークアップすることで、AIは「この情報は専門家が発信している」と認識しやすくなります。
AuthoritativenessとTrustworthinessの構築
権威性と信頼性は、一朝一夕には構築できません。長期的な取り組みが必要な領域です。
権威性を高めるためには、他の信頼できるサイトからの言及や引用を獲得することが重要です。業界メディアへの寄稿、プレスリリースの発信、セミナーやウェビナーでの登壇など、オフサイトでの活動が権威性の構築に寄与します。
信頼性については、サイト運営者の情報開示、プライバシーポリシーの整備、セキュリティ対策(HTTPS化)、正確な連絡先情報の提示といった基本的な要素が土台となります。
医療機関での引用率向上事例として、医師の経歴を「学歴+症例数+学会発表」の形式で明記し、治療法の根拠を医学論文ヘリンクさせた結果、GPT-5での疾病解説引用率が58%増加したという報告もあります。E-E-A-Tの各要素を具体的かつ検証可能な形で示すことが、LLMO時代には一層重要になっているのです。
具体的なコンテンツ設計フレームワーク

ここからは、LLMOコンテンツ要件を満たすための実践的な設計手法を解説します。理論だけでなく、明日から使えるフレームワークとしてまとめました。
結論ファースト構造の徹底
AIに引用されやすいコンテンツの第一条件は、結論が明確に示されていることです。
PREP法(Point Reason Example Point) やSDS法 (Summary Details Summary)といった論理構造を意識的に使用することで、AIが「このコンテンツは○○という結論を述べている」と認識しやすくなります。
実装のポイントとして、各セクションの冒頭1~2文で要点を述べることを徹底してください。その後に詳細な説明や具体例を展開する形にすることで、AIは冒頭部分を引用しやすくなります。
Q&A形式コンテンツの効果的な配置
生成AIは「質問に対する回答を生成する」という仕組みで動作するため、Q&A形式のコンテンツは極めて引用されやすい形式です。
効果的なQ&Aコンテンツを作成する際のポイントは以下の通りです。
▼ Q&Aコンテンツ設計のポイント
- 実際にユーザーが検索しそうな形式で質問を設定する(「○○とは?」「○○と△△の違いは?」など)
- 回答は1~3文で端的に示し、詳細説明はその後に展開する
- FAQPageスキーマで構造化データとしてマークアップする
- 関連する質問をグループ化し、テーマごとにまとめる
特に「○○とは?」 「○○にはいくらかかるのか?」 「○○と△△のどちらがよいか?」といった定義・費用・比較に関する質問は、AIの回答生成において頻繁に参照される傾向にあります。
HTMLセマンティクスを活用した構造設計
HTML5のセマンティックタグを適切に使用することで、AIはコンテンツの論理構造をより正確に理解できるようになります。
article、section、header、main、footerといったタグは、単なるデザイン上の区切りではなく、コンテンツの意味的な構造を示すものです。これらを適切に使用することで、AIは「この部分が本文である」「この部分が関連情報である」といった判断を正確に行えます。
また、見出しタグ (H1~H6)の階層構造を論理的に保つことも重要です。H2の後にいきなりH4が来るような構造は、AIの理解を妨げる要因になります。
信頼できる情報源への適切なリンク
コンテンツ内で主張やデータを示す際には、その根拠となる情報源へのリンクを明示することが重要です。
特に政府機関、学術機関、業界団体など権威性の高い情報源へのリンクは、コンテンツ全体の信頼性を高める効果があります。AIは「このコンテンツは信頼できる情報源を参照している」と認識し、引用への安心感を持つことになります。
ただし、アフィリエイトリンクばかりが並んでいるようなコンテンツは、信頼性が低いと判断される可能性があります。引用目的のリンクと収益目的のリンクのバランスには注意が必要です。
LLMOコンテンツで避けるべき5つの落とし穴

要件を満たすことと同様に重要なのが、AIに評価されにくいコンテンツのパターンを避けることです。以下に挙げる落とし穴は、多くのサイトで見られる共通の課題です。
キーワードの過剰な詰め込み
従来のSEOでは一定の効果があったキーワードの繰り返しですが、LLMOにおいては逆効果になる可能性が高いといえます。
AIは文脈を理解して情報を処理するため、不自然なキーワードの羅列は「低品質なコンテンツ」として認識される恐れがあります。各種研究でも、コンテンツに関連キーワードを無理に追加しても引用率向上には効果がないことが示されています。
自然な文章の中でキーワードが適切に使用されていることが、AIにとっては好ましい状態です。
被リンク依存の思考
SEOでは被リンク数が重要な指標でしたが、LLMOにおける被リンクの効果は限定的とされています。
AIがコンテンツを選ぶ際に重視するのは、リンクの数ではなくコンテンツ自体の質と信頼性です。被リンク獲得に労力を割くよりも、コンテンツの専門性向上や構造化データの実装に注力したほうが、LLMO対策としては効果的といえます。
曖昧な表現や回りくどい説明
「~といわれています」 「~の可能性があります」といった曖昧な表現の多用は、AIにとって引用しにくいコンテンツを生み出します。
AIは明確で断定的な情報を好む傾向があります。もちろん不確実な情報を断定的に述べることは問題ですが、確実な事実については明確に言い切る形で表現したほうが、引用される可能性は高まります。
また、長い前置きや冗長な説明も避けるべきです。AIは要点を抽出して使用するため、要点が埋もれているコンテンツは引用対象として選ばれにくくなります。
JavaScriptレンダリングへの過度な依存
技術的な観点から見落としがちなのが、AIクローラーの多くがJavaScriptをレンダリングせずにHTMLのみを取得しているという事実です。
React、Vue、Angularなどのフレームワークで構築されたサイトで、重要なコンテンツがJavaScriptで動的に生成される場合、AIはそのコンテンツを認識できない可能性があります。
サーバーサイドレンダリング (SSR)の実装や、重要なコンテンツを静的HTMLとして出力する設計が、LLMO対策においては重要になります。
更新日の非表示
コンテンツの更新日を表示していないサイトは意外に多いですが、これはLLMO対策において大きな機会損失です。
AIは情報の鮮度を重視するため、更新日が不明なコンテンツより、明確に更新日が示されているコンテンツを優先します。datePublishedとdateModifiedを構造化データとして実装することで、AIに対して情報の鮮度を明示的に伝えることができます。
コンテンツ要件を満たすための技術的実装

LLMOコンテンツ要件を満たすためには、コンテンツの質だけでなく技術的な実装も重要です。ここでは、実務で押さえておくべき技術要素を解説します。
構造化データの具体的な実装方法
構造化データはJSON-LD形式で実装することが推奨されています。HTMLのhead要素またはbody要素内にスクリプトとして記述します。
たとえば記事ページの場合、Articleスキーマを使用して以下の情報をマークアップします。
▼ Articleスキーマで設定すべき主要プロパティ
- headline(記事タイトル)
- author(著者情報、Personスキーマでネスト)
- datePublished(公開日)
- dateModified (更新日)
- publisher(発行元、Organizationスキーマでネスト)
- description(記事の要約)
実装後はGoogleの「リッチリザルトテスト」で検証することが必須です。エラーや警告がある場合、AIが構造化データを正しく認識できない可能性があります。
llms.txtファイルの設置
llms.txtは、AIクローラーに対してサイトの概要や重要なページを伝えるためのファイルです。robots.txtがクローラーの動作を制御するものであるのに対し、llms.txtはAIに対して「このサイトで重要な情報はこれです」と伝える役割を持ちます。
ファイルはサイトのルートディレクトリに設置し、サイトの概要、主要なコンテンツカテゴリ、重要なページへのリンクなどを記述します。まだ標準化された仕様ではありませんが、AI対応の先進的な施策として注目されています。
AIクローラーのアクセス許可確認
robots.txtでAIクローラーをブロックしていないか確認することも重要です。
GoogleのGoogle-Extended、OpenAIのGPTBot、AnthropicのClaudeBot、MicrosoftのBingbotなど、主要なAIクローラーがサイトにアクセスできる状態になっているか確認してください。意図せずブロックしている場合、AI Overviewやその他のAI検索で情報が参照されない原因となります。
ページ表示速度の最適化
LLMOにおいても、従来のSEOと同様にページ表示速度は重要な要素です。
AIクローラーは大量のページを処理するため、表示速度が遅いサイトはクロール効率が下がります。また、Core Web Vitalsに代表されるUX指標は、AI検索においても引き続き重要視されていると考えられています。
画像の最適化、不要なスクリプトの削除、CDNの活用など、基本的な表示速度改善施策は継続して実施すべきです。
LLMOコンテンツ要件の効果測定方法

LLMOの効果測定は、従来のSEOと比較して困難な面があります。しかし、いくつかの指標を組み合わせることで、施策の効果を把握することは可能です。
手動での引用確認
最もシンプルな方法は、ChatGPT、Gemini、Perplexityなどの生成AIに対して、自社に関連するキーワードで質問し、回答に自社が引用・言及されているか確認することです。
定期的に(週1回程度) チェックを行い、引用頻度の変化を記録することで、施策の効果を大まかに把握できます。AIの回答は確定的ではないため、複数回質問して傾向を見ることが重要です。
GA4でのAI経由流入の計測
Google Analytics 4では、生成AI経由のトラフィックを識別することが可能です。
参照元として「chat.openai.com」「gemini.google.com」 「perplexity.ai」などが記録されている場合、それがAI検索経由の流入です。これらの流入数の推移を追跡することで、LLMOの成果を定量的に把握できます。
ただし、AI Overviewからの流入は通常のGoogle検索として記録されるため、純粋なAI検索流入とは区別できない点に注意が必要です。
専用ツールの活用
LLMO対策の効果測定に特化したツールも登場しています。otterly.AI、ZipTie、SE Rankingなどのツールは、AIにおける自社の言及・引用状況を追跡する機能を提供しています。
本格的にLLMO対策に取り組む場合は、これらのツールの導入を検討する価値があるでしょう。
指名検索の変化
AIに言及されることによるブランディング効果は、指名検索(ブランド名での検索)の増加として現れることがあります。
Google Search Consoleでブランド関連キーワードのインプレッション・クリック数の推移を追跡することで、間接的なLLMO効果を測定できます。非指名キーワードでのインプレッション増加も、AIがコンテンツを認識・活用している兆候として捉えることができます。
業種別のLLMOコンテンツ要件対応ポイント

LLMOコンテンツ要件への対応方法は、業種によって重点を置くべきポイントが異なります。ここでは、主要な業種別の対応ポイントを解説します。
来店型ビジネス(飲食店・小売・サービス業)
来店型ビジネスでは、ローカル情報の正確性が極めて重要です。
Googleビジネスプロフィールの情報とWebサイトの情報が一致していること、NAP情報(Name Address・Phone)が統一されていること、営業時間やサービス内容が最新の状態に保たれていることが、AIに正確な情報を伝える前提条件となります。
また、Local Business スキーマの実装、口コミ情報の適切な管理、よくある質問(営業時間、予約方法、アクセス方法など)のFAQ形式での整備が効果的です。
BtoB企業
BtoB企業では、専門性の証明がより重要になります。
業界特有の課題に対する深い知見、具体的な導入事例や成果データ、専門家による監修や執筆といった要素が、AIに「信頼できる情報源」として認識されるポイントになります。
ホワイトペーパーやケーススタディをFAQ形式で要約したコンテンツを用意することで、AIが参照しやすい形式で専門情報を提供できます。
医療・健康分野
医療・健康分野は、E-E-A-Tが最も厳格に求められる分野です。
医師や医療専門家による監修の明示、エビデンスに基づく情報提供、信頼できる医学文献への引用が必須となります。また、情報の更新日を明示し、ガイドラインの改定に合わせてコンテンツを更新する体制も重要です。
この分野では、不正確な情報がAIを通じて拡散されるリスクがあるため、AIも特に慎重に情報源を選別していると考えられています。
EC・小売 (オンライン)
EC分野では、商品情報の構造化が重要です。
Productスキーマを使用した商品情報のマークアップ、レビュー情報の適切な構造化、価格情報の最新化が基本となります。また、「○○と△△の違い」 「○○の選び方」といった比較・購入検討段階のコンテンツを充実させることで、AIの商品レコメンデーションに採用される可能性が高まります。
LLMOコンテンツ要件への対応は株式会社トリニアスにご相談ください
LLMOコンテンツ要件への対応は、単なるテクニカルな施策ではなく、コンテンツ戦略全体の見直しを伴う取り組みです。SEOの基盤を持ちながら、AI時代の新しい要件に対応していくには、体系的なアプローチが必要になります。
マケスクを運営する株式会社トリニアスは、2017年からMEO (Map Engine Optimization)を中心としたローカルビジネス向けデジタルマーケティングを展開し、累計5,000社以上の支援実績を持ちます。上位表示達成率96.2%という実績は、検索エンジンの評価基準を深く理解してきた証です。
この知見は、AI検索時代においても大きな強みとなります。なぜなら、AIが参照する情報源の多くは検索エンジンで評価されたコンテンツであり、SEO・MEOで培ったE-E-A-Tの構築ノウハウは、そのままLLMO対策に応用できるからです。
地域に根ざしたビジネスにとって、AI検索対応は「いつか取り組むべきこと」ではなく、すでに競争優位を左右する重要な要素になりつつあります。お客様のビジネス特性を踏まえた最適なLLMOコンテンツ戦略について、ぜひトリニアスまでご相談ください。
株式会社トリニアス | MEO prime
導入企業数:累計5,000社以上
上位表示達成率:96.2%
MEO SNS HP × ロコミ対策まで一貫した集客支援を提供
LLMO 関連記事
- 島根でLLMO対策業者を探す|選び方と依頼先の候補を紹介
- 鳥取のLLMO対策業者の選び方|AI検索で選ばれる店舗になるための実践ポイント
- 長野県のLLMO対策業者の選び方|費用相場から依頼時の注意点まで解説
- 長崎でLLMO対策業者を選ぶ前に知っておきたい基礎知識と業者選定のコツ
- 大分のLLMO対策業者を徹底比較|AI検索時代に選ばれる店舗になるための選び方と具体策
- 大阪のLLMO対策業者を選ぶ視点|費用相場と失敗しない依頼のコツ
- 千葉のLLMO対策業者を選ぶポイント|費用相場とAI検索で選ばれるための施策
- 石川でLLMO対策業者を選ぶポイント|AI検索時代の集客戦略と業者比較
- 静岡でLLMO対策業者を選ぶ際の着眼点|AI検索時代の集客戦略と業者比較
- 青森でLLMO対策業者を探す前に知っておきたいAI検索時代の集客戦略と実践ポイント