LLMOの構造化データとは?AI検索で認識されやすいマークアップ方法


ChatGPTやGoogleのAI Overviewなど、生成AIによる検索体験が急速に普及しています。従来のSEO対策では「検索結果の上位表示」がゴールでしたが、AI検索時代においては「AIに引用される」ことが新たな集客の鍵となりました。
この変化に対応するための施策がLLMO (Large Language Model Optimization=大規模言語モデル最適化)です。そしてLLMO対策において特に重要な役割を果たすのが構造化データの実装になります。
構造化データとは、Webページの情報を検索エンジンやAIが理解しやすい形式で記述したマークアップのこと。店舗名、住所、営業時間、商品価格、FAQの質問と回答といった情報を、AIが「意味」として認識できるよう整理して伝える技術です。
本記事では、LLMO対策における構造化データの役割から、具体的な実装方法、効果検証の仕方まで、実践的なノウハウをお伝えします。地域ビジネスのWeb集客を支援してきたトリニアスの知見をもとに、AIに「選ばれる」サイトづくりのポイントを解説していきましょう。
LLMOとSEOの違いを押さえる

LLMO対策を正しく理解するには、まず従来のSEOとの違いを把握しておく必要があります。両者は似ているようで、目指すゴールが根本的に異なるためです。
SEOは「検索上位表示」、LLMOは「AI引用」が目的
SEO (Search Engine Optimization)は、Googleなどの検索エンジンで上位表示を獲得し、検索結果からのクリック流入を増やすことが目的でした。キーワードの最適化、被リンクの獲得、ページ速度の改善といった施策が中心となります。
一方、LLMOは生成AIが回答を作成する際に、自社コンテンツを情報源として引用させることを目指します。ChatGPTやPerplexity、GoogleのAI Overviewなどが回答を生成するとき、どのWebサイトの情報を参照するかが重要になるわけです。
AIに引用されると、回答文の中に出典としてサイトへのリンクが表示されます。ユーザーがそのリンクをクリックすればアクセスにつながりますし、何度も引用されることでブランド認知の向上にも寄与します。
キーワード重視から「文脈と構造」重視へ
SEOではキーワードの出現頻度や配置が重視されてきました。しかしLLMOでは、AIがコンテンツの「意味」を正確に理解できるかどうかが問われます。
AIは膨大なWebページの中から情報を取得し、ユーザーの質問に対する回答を生成します。このとき、情報が論理的に整理され、文脈が明確なコンテンツほど引用されやすくなるのです。見出し構造の一貫性、段落ごとの論点の明確さ、そして構造化データによる意味の明示が、LLMO対策の核心といえるでしょう。
両立は可能か? SEOとLLMOの関係性
結論から言えば、SEOとLLMOは対立するものではなく、相互に補完し合う関係にあります。
実際、生成AIが回答を生成する際には、検索上位に表示されているページの情報を参照する傾向が確認されています。つまり、SEOで高い評価を得ているサイトは、LLMOでも有利になりやすいのです。
ただし、SEO対策だけでは不十分な面もあります。AIが情報を「理解」し「引用」するためには、構造化データの実装やコンテンツの論理構造の最適化といった、LLMO固有の対策が求められます。
AI時代の新しい購買行動モデル「AIMA5」とは
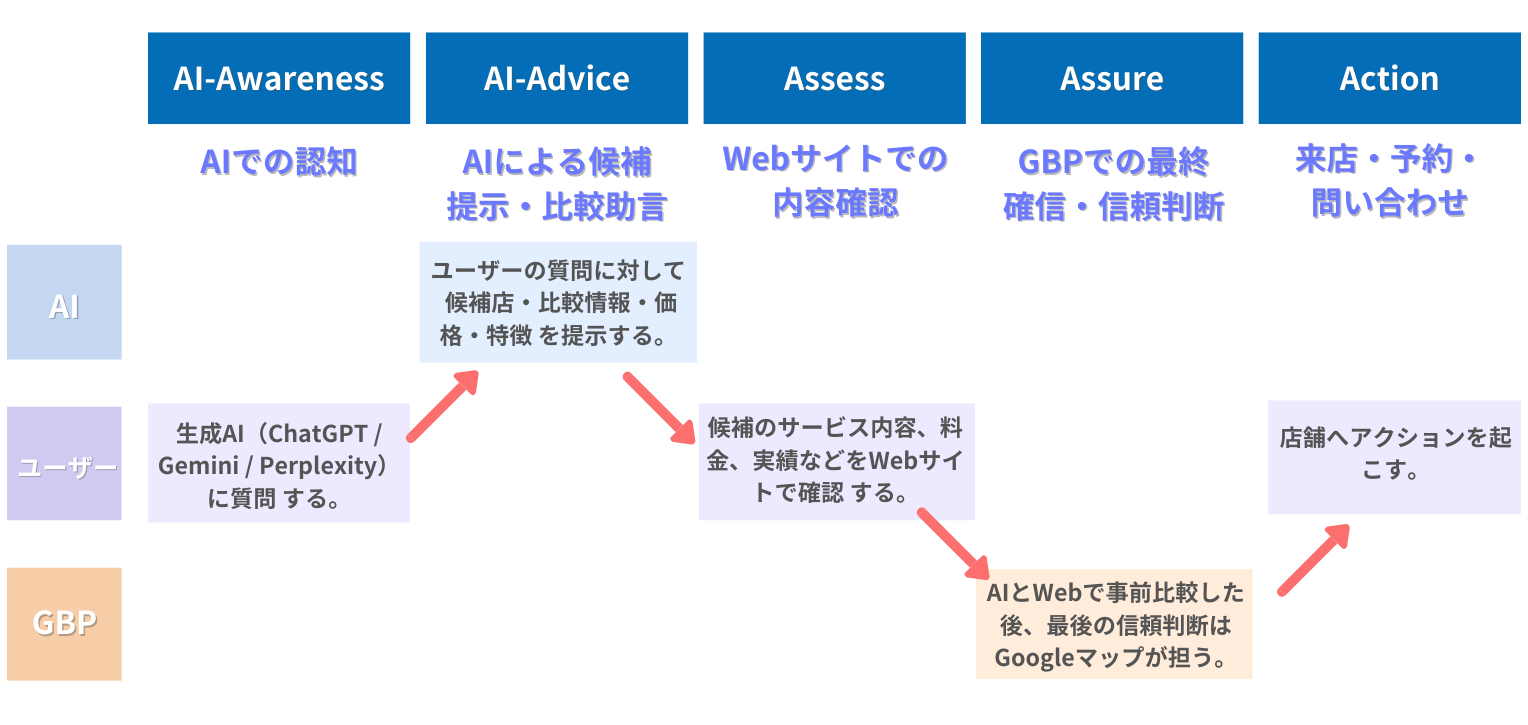
近年、消費者の情報収集方法は大きく変化しています。従来のGoogle検索だけでなく、ChatGPTやGemini、PerplexityなどのAI検索を活用して店舗やサービスを探す人が急増しているのです。
こうしたAI時代の購買行動を体系化したのが「AIMA5 (アイマファイブ)」です。AIMA5は、消費者が店舗を認知してから来店するまでの流れを、以下の5つのステップで整理しています。
- AI-Awareness (AI認知): AI検索で店舗名が表示される
- AI-Advice (AI助言): AIが理由を持っておすすめする
- Assess (Webで深く検討): 公式サイトで詳細を確認する
- Assure (Googleマップで確信): クチコミや写真で最終判断する
- Action(行動): 予約・問い合わせ・来店する
このモデルの特徴は、購買行動の起点が「AI検索」になっている点です。AIに認知され、おすすめされる状態を作ることが、これからの集客において重要な鍵となります。
LLMOは、このAIMA5における最初の2ステップ「AI-Awareness」と「AI-Advice」を強化するための施策です。AI検索で選ばれる店舗になるために、今から準備を始めましょう。
AIMA5の詳細はこちら
構造化データがLLMOで重要な理由

では、なぜ構造化データがLLMO対策において重要なのでしょうか。その理由を技術的な観点から掘り下げてみましょう。
AIは「意味」を理解するために構造化データを活用する
人間がWebページを見れば、「これは店舗の住所だ」 「これは営業時間だ」と自然に理解できます。しかしAIにとって、HTMLのテキストは単なる文字列の羅列でしかありません。
構造化データは、この情報に「意味」を付与する役割を果たします。「これは組織名です」「これは住所です」「これは電話番号です」といったラベルを付けることで、AIが情報の種類を正確に認識できるようになるのです。
GoogleのAI Overview や ChatGPTなどのLLMは、構造化データを手がかりにしてページの内容を解釈し、ユーザーへの回答に活用します。構造化されていない情報よりも、明確にマークアップされた情報のほうが、引用元として選ばれやすくなります。
リッチリザルト表示とAI Overview掲載の両方に効果
構造化データの実装は、従来のSEOにおいてもリッチリザルト(検索結果での強調表示)を獲得するために有効な施策でした。星評価、価格、FAQの展開表示などが検索結果に表示されることで、クリック率の向上が期待できます。
LLMO時代においては、この効果に加えて、AI Overviewに掲載される確率が高まるというメリットが加わります。構造化データによって情報が整理されたページは、AIが要約・引用しやすいため、AI検索結果の上部に表示される確率が高まるのです。
つまり、構造化データへの投資は、SEOとLLMOの両方にリターンをもたらす、費用対効果の高い施策といえます。
E-E-A-T評価を補強するシグナルになる
Googleが重視するE-E-A-T (Experience: 経験、Expertise: 専門性、Authoritativeness:権威性、Trustworthiness: 信頼性)は、AI検索においても重要な評価基準です。
構造化データで著者情報、組織情報、公開日、更新日などを明示することで、コンテンツの信頼性をAIに伝えることができます。「誰が」「いつ」「どのような立場で」情報を発信しているのかを明確にすることで、AIは情報源としての信頼性を判断しやすくなります。
特に医療、法律、金融といったYMYL (Your Money or Your Life) 領域では、E-E-A-Tの評価が厳格に行われます。構造化データによる信頼性の明示は、こうした領域でのLLMO対策において不可欠な要素となっています。
Schema.orgとJSON-LDの基礎知識

構造化データを実装するうえで欠かせないのが、Schema.orgとJSON-LDという2つの概念です。技術的な詳細に入る前に、まずはこれらの基本を押さえておきましょう。
Schema.orgとは何か
Schema.org (スキーマ・オルグ)は、Google、Microsoft (Bing)、Yahoo!、Yandexといった主要な検索エンジンが共同で策定した、構造化データの「語彙集」です。Webページ上のさまざまな情報(記事、商品、イベント、人物、組織、レビュー、レシピ、FAQなど)を記述するための標準化されたルールを提供しています。
Schema.orgを使うことで、世界中の検索エンジンやAIに対して、統一された方法で情報を伝えることができます。独自のフォーマットで記述しても、AIが理解できなければ意味がありません。国際標準に準拠することが、LLMO対策の第一歩なのです。
JSON-LD形式が推奨される理由
構造化データの記述形式には、Microdata、RDFa、JSON-LDの3種類があります。このうち、Googleが推奨しているのはJSON-LD (JavaScript Object Notation for Linked Data)です。
JSON-LDの最大の特徴は、HTMLの本文とは別に、<script> タグ内に記述できること。既存のHTML構造を変更することなく、構造化データを追加できるため、実装や管理が容易です。また、可読性が高く、修正やメンテナンスもしやすいというメリットがあります。
MicrodataやRDFaはHTMLタグに直接属性を追加する形式のため、既存コードの改修が必要になるケースが多く、運用負荷が高くなりがちです。特別な理由がない限り、JSON-LD形式での実装をおすすめします。
基本構文と主要プロパティ
JSON-LDの基本構文は以下のようになります。
“JSON-LD基本構文の例”
<script type=”application/ld+json”>
{
“@context”: “https://schema.org”,
“@type”: “LocalBusiness”,
“name”: “店舗名”,
“address”: {
“@type”: “PostalAddress”,
“streetAddress”: “○○町1-2-3”,
“addressLocality”: “○○市”,
“addressRegion”:”東京都”,
“postalCode”: “123-4567”
},
“telephone”: “03-1234-5678”
}
</script>
主要なプロパティの意味を整理しておきましょう。
| プロパティ | 説明 |
| @context | 使用する語彙を指定(通常は https://schema.org) |
| @type | データの種類 (Article、LocalBusiness、FAQPageなど) |
| @id | エンティティを一意に識別するための URI |
| name | 名称(店舗名、記事タイトルなど) |
| sameAs | 他サイト上の同一エンティティへのリンク( SNSなど) |
LLMOに効果的な構造化データのタイプ
Schema.orgには数百種類のタイプ(スキーマ)が用意されていますが、すべてを実装する必要はありません。LLMO対策において特に効果が高いとされるタイプを優先的に実装することが重要です。
Local Business (ローカルビジネス)
店舗や事業所を持つビジネスにとって、LocalBusinessスキーマは最優先で実装すべきタイプです。店舗名、住所、電話番号、営業時間、対応エリアなどの基本情報をAIに正確に伝えることができます。
MEO(Map Engine Optimization) 対策とも密接に関連しており、Googleビジネスプロフィールとの情報の一貫性を保つことで、地域検索における評価向上にも寄与します。
飲食店であればRestaurant、歯科医院であればDentist、美容サロンであればBeautySalonなど、LocalBusinessのサブタイプを使い分けることで、より詳細な情報をAIに伝えられます。
FAQPage (よくある質問)
FAQPageスキーマは、LLMO対策において非常に効果的なタイプの一つです。質問と回答のペアを明確に構造化することで、AI Overviewに掲載される確率が高まることが確認されています。
生成AIは、ユーザーからの質問に対して適切な回答を提示することを目的としています。FAQPageスキーマで「質問」と「回答」を明示しておけば、AIはその情報を優先的に参照し、回答に引用しやすくなるのです。
業種を問わず、お客様からよく寄せられる質問をFAQページとして整備し、構造化データを実装することをおすすめします。
Article / Blog Posting (記事・ブログ投稿)
ブログやコラムなどの記事コンテンツには、ArticleまたはBlogPostingスキーマを実装します。記事タイトル、著者、公開日、更新日、アイキャッチ画像などの情報をAIに伝えることで、コンテンツの信頼性評価を高める効果が期待できます。
特に「著者情報」の明示は重要です。誰が書いた記事なのかを構造化データで示すことで、E-E-A-Tの評価においてプラスに働きます。著者のプロフィールページへのリンクや、著者のSNSアカウント情報をsameAsプロパティで紐づけることも有効でしょう。
Organization(組織情報)
企業や団体の公式情報を定義するOrganizationスキーマも、LLMO対策の基盤となる重要なタイプです。組織名、ロゴ、所在地、連絡先、公式SNSアカウントなどを構造化することで、AIが組織を「エンティティ」として正確に認識できるようになります。
Googleのナレッジグラフに登録されることにも寄与し、ブランドの権威性向上につながります。特に、sameAsプロパティでWikipediaや公式SNSへのリンクを記述することで、組織の実在性と信頼性を示すことができます。
HowTo(手順解説)
「○○のやり方」 「△△の手順」といったハウツーコンテンツには、HowToスキーマが効果的です。手順をステップごとに構造化することで、AIが情報を抽出しやすくなり、AI Overviewでの掲載につながりやすくなります。
各ステップの所要時間や必要な道具・材料なども記述できるため、レシピサイトやDIY系のコンテンツとの相性が特に良いスキーマです。
Product/Review (商品・レビュー)
ECサイトや商品紹介ページでは、Productスキーマの実装が推奨されます。商品名、価格、在庫状況、レビュー評価などを構造化することで、検索結果でのリッチリザルト表示に加え、AIが商品情報を正確に把握するのに役立ちます。
AggregateRating (総合評価)を併用することで、ロコミ評価の情報もAIに伝えることができ、商品選定に関するAI検索での露出向上が期待できます。
構造化データの実装手順
ここからは、実際に構造化データを実装するための具体的な手順を解説します。WordPressサイトを想定した方法を中心に説明しますが、他のCMSや静的サイトでも基本的な考え方は同じです。
ステップ1: 対象ページとスキーマタイプを決定する
まずは、構造化データを実装するページと、使用するスキーマタイプを決めます。すべてのページに同時に実装しようとすると作業量が膨大になるため、優先順位をつけて段階的に進めることをおすすめします。
▼優先的に実装すべきページの例
- トップページ → Organization、WebSiteスキーマ
- 店舗・会社概要ページ → LocalBusinessスキーマ
- FAQページ → FAQPageスキーマ
- ブログ記事→ ArticleまたはBlogPostingスキーマ
- サービス紹介ページ → Service、Productスキーマ
ステップ2: JSON-LDコードを作成する
スキーマタイプが決まったら、JSON-LD形式でコードを作成します。手動で記述することも可能ですが、文法エラーを防ぐために構造化データ生成ツールの利用をおすすめします。
代表的なツールとしては、Google公式の「Schema Markup Generator」や、「Technical SEO」が提供するジェネレーターがあります。必要な情報をフォームに入力するだけで、正しいフォーマットのJSON-LDコードが自動生成されます。
生成されたコードは、内容を確認してから使用しましょう。特に、URL、電話番号、住所などの正確性は入念にチェックしてください。
ステップ3: サイトに実装する
作成したJSON-LDコードをWebサイトに設置します。実装方法は主に3つあります。
方法1: HTMLの<head>タグ内に直接記述する
最もシンプルな方法です。WordPressの場合、テーマのheader.phpファイルや、カスタムヘッダーに追加できます。ただし、テーマの更新時に上書きされるリスクがあるため、子テーマの使用を推奨します。
方法2: WordPressプラグインを使用する
「Rank Math」 「Yoast SEO」 「All in One SEO」などのSEOプラグインには、構造化データを自動生成・管理する機能が備わっています。プラグインの設定画面から必要な情報を入力するだけで実装できるため、コードに不慣れな方にはこの方法がおすすめです。
プラグインは定期的にアップデートされるため、Googleの仕様変更にも対応しやすいというメリットもあります。
方法3: Googleタグマネージャー (GTM)を使用する
HTMLを直接編集せずに構造化データを設置したい場合は、GTMの「カスタムHTMLタグ」機能を活用できます。GTMの管理画面でJSON-LDコードを入力し、トリガーを設定するだけで実装が完了します。
ステップ4: 実装結果を検証する
構造化データを設置したら、正しく実装されているか必ず検証しましょう。検証には以下のツールを使用します。
Googleリッチリザルトテスト (https://search.google.com/test/rich-results)
URLまたはコードを入力すると、リッチリザルトの対象となるかどうかを判定し、エラーや警告があれば表示してくれます。
Schema Markup Validator(Schema.org公式)
Schema.orgの仕様に準拠しているかをチェックできます。Googleのツールでは検出されない細かなエラーも発見できるため、併用をおすすめします。
Google Search Console
実装後、Google Search Consoleの「拡張」セクションで構造化データの認識状況を確認できます。エラーや警告が表示された場合は、速やかに修正しましょう。
llms.txtの役割と実装方法

構造化データと並んで、LLMO対策で注目されているのが「llms.txt」というファイルです。これはSchema.orgとは異なるアプローチで、AIにサイト情報を伝えるための仕組みです。
llms.txtとは何か
llms.txtは、AIに対してWebサイトの構造や重要なコンテンツを効率的に伝えるためのテキストファイルです。robots.txtがクローラーに対して巡回ルールを伝えるように、llms.txtはAIに対してサイトの「案内書」のような役割を果たします。
Markdown形式で記述し、サイトのルートディレクトリ (robots.txtと同じ階層)に設置します。サイトの名称、概要、主要なページへのリンク、優先的に参照してほしいコンテンツなどを記述することで、AIがサイト全体を効率的に理解できるようになります。
llms.txtの基本構造
llms.txtの記述例を見てみましょう。
“llms.txtの記述例”
#株式会社○○
> ○○市で創業30年の地域密着型リフォーム会社です。
> 住宅リフォーム、外壁塗装、水回りリフォームを専門としています。
## 主なサービス
– [住宅リフォーム] (https://example.com/reform/): 戸建て・マンションの内装リフォーム
– [外壁塗装](https://example.com/painting/): 外壁・屋根塗装のプロフェッショナル
– [水回りリフォーム] (https://example.com/water/): キッチン・浴室・トイレの改修
## よくある質問
– [FAQ](https://example.com/faq/): お客様からよくいただくご質問と回答
## 会社情報
– 所在地:○○県○○市○○町1-2-3
– 電話番号:0120-xxx-xxx
ファイル名は「llms.txt」として保存し、文字コードはUTF-8で作成します。より詳細な情報を含める場合は「llms-full.txt」を別途用意することも推奨されています。
llms.txtの効果と注意点
現時点では、llms.txtはすべてのAIクローラーに認識されるわけではありません。公式な標準規格ではなく、提案段階の仕様であるためです。
ただし、将来的にAI検索の標準的な対策手法になる可能性が指摘されており、早期に実装しておくことで先行者利益を得られる可能性があります。実装自体は非常に簡単で、マイナスの影響はないため、LLMO対策の一環として設置しておくことをおすすめします。
robots.txtとの違いを押さえておくことも重要です。robots.txtは検索エンジンのクローラーに対する巡回ルールを指定するもの、llms.txtはAIの情報活用を支援するための案内書という位置づけです。目的が異なるため、両方を設置することが推奨されます。
構造化データ実装でよくある失敗と対策

構造化データの実装において、よくある失敗パターンとその対策を紹介します。せっかく実装しても、これらのミスがあると効果が得られないどころか、ペナルティの原因になることもあります。
JSONの文法エラー
最も多い失敗が、JSON形式の文法エラーです。カンマの忘れ、閉じ括弧の不足、シングルクォートとダブルクォートの混同などがあると、構造化データは一切認識されません。
対策としては、構造化データ生成ツールを使用することと、実装後に必ず検証ツールでチェックすることが挙げられます。JSONLint(https://jsonlint.com/)などの構文チェック専用ツールも活用しましょう。
ページ内容と構造化データの不一致
構造化データに記述した情報と、実際のページに表示されている情報が一致していないケースも問題です。たとえば、構造化データでは「営業時間9:00~18:00」と記述しているのに、ページ本文では「10:00~17:00」と表示されている場合、Googleのガイドライン違反となります。
構造化データは、ページに実際に表示されている情報を「マークアップ」するものであり、ユーザーに見えない情報を埋め込む手段ではありません。情報の整合性を常に保つよう注意してください。
不適切なスキーマタイプの選択
本来「Product」型でマークアップすべき商品情報に「BlogPosting」型を使用するなど、スキーマタイプの誤用も散見されます。AIや検索エンジンの解釈に齟齬が生じ、リッチリザルト非対応や評価低下の原因になりかねません。
Schema.orgの公式ドキュメントで、各タイプの用途と適用範囲を確認してから実装しましょう。迷った場合は、より汎用的な親タイプ(たとえばLocalBusinessの代わりにOrganization)を選択するのも一つの方法です。
必須プロパティの欠落
スキーマタイプごとに、リッチリザルト表示に必要な「必須プロパティ」と「推奨プロパティ」が定められています。必須プロパティが欠けていると、エラーとなってリッチリザルトに表示されません。
Googleの検索セントラルドキュメントで、各スキーマタイプの必須プロパティを確認し、漏れなく記述するようにしましょう。
LLMO対策の効果測定と改善サイクル

構造化データを実装したら、その効果を測定し、継続的に改善していくことが重要です。LLMO対策はSEOと同様に、一度実施して終わりではなく、PDCAサイクルを回していく必要があります。
効果測定の指標
LLMO対策の効果を測定するための指標は、従来のSEO指標とは一部異なります。
AI検索からの流入数
Google Analyticsのトラフィックソースを分析し、AI検索 (ChatGPT、Perplexityなど)からの流入を把握します。リファラー情報から、どのAIサービス経由でアクセスがあったかを確認できます。
AI Overviewでの表示状況
主要なキーワードで検索し、自社サイトがAI Overviewに引用されているかを定期的にチェックします。手動での確認が基本となりますが、ツールを活用して効率化することも可能です。
指名検索数の推移
AIに繰り返し引用されることで、ブランド認知が向上し、社名や店舗名での「指名検索」が増加する傾向があります。Google Search Consoleで指名検索クエリの推移をモニタリングしましょう。
リッチリザルト表示率
Google Search Consoleの「検索での見え方」レポートで、リッチリザルトの表示回数とクリック率を確認できます。構造化データの実装がSEO面でも効果を発揮しているかを測る指標になります。
改善サイクルの回し方
効果測定の結果をもとに、以下のような改善を継続的に行っていきます。
AI Overviewに表示されているページの特徴を分析し、成功パターンを他のページにも展開する。エラーや警告が出ている構造化データを修正する。競合サイトのLLMO対策を調査し、自社に取り入れられる施策がないか検討する。新しいスキーマタイプの追加実装を検討する。
AIの進化は非常に速いため、3~6ヶ月ごとに施策の見直しを行うことをおすすめします。Google公式の最新情報やLLMO関連のニュースにもアンテナを張っておきましょう。
LLMO時代に対応したWeb集客は株式会社トリニアスにご相談ください

AI検索の普及により、Web集客の在り方は大きな転換期を迎えています。従来のSEO対策に加えて、LLMOへの対応が求められる時代になりました。
構造化データの実装は、SEOとLLMOの両方に効果をもたらす重要な施策です。本記事で解説したJSON-LDによるマークアップ、llms.txtの設置、そして継続的な効果測定と改善を通じて、AIに「選ばれる」 サイトづくりを進めていきましょう。
株式会社トリニアスが運営するマケスクでは、地域ビジネスのWeb集客を総合的にサポートしています。MEO対策で培ってきたGoogleビジネスプロフィールの最適化ノウハウに加え、構造化データの実装支援、LLMO時代に対応したコンテンツ設計のご提案も行っています。
2017年のサービス開始以来、累計5,000社以上の地域ビジネスを支援し、上位表示達成率96.2%という実績を積み重ねてきました。「AIにも、お客様にも選ばれる店舗づくり」を目指す方は、ぜひお気軽にご相談ください。
マケスクのサービス内容
MEO prime (Googleマップ最適化)、ロコミ管理、ホームページ制作、SNS運用代行など、地域ビジネスの集客に必要な施策をワンストップでご提供しています。まずは無料相談から、貴社の課題をお聞かせください。
LLMO 関連記事
- 大阪のLLMO対策業者を選ぶ視点|費用相場と失敗しない依頼のコツ
- 千葉のLLMO対策業者を選ぶポイント|費用相場とAI検索で選ばれるための施策
- 石川でLLMO対策業者を選ぶポイント|AI検索時代の集客戦略と業者比較
- 静岡でLLMO対策業者を選ぶ際の着眼点|AI検索時代の集客戦略と業者比較
- 青森でLLMO対策業者を探す前に知っておきたいAI検索時代の集客戦略と実践ポイント
- 神奈川でLLMO対策業者を選ぶポイント|AI検索時代の集客戦略と業者比較
- 新潟でLLMO対策業者を探す前に知っておきたいAI検索時代の集客戦略と実践ポイント
- 秋田のLLMO対策業者おすすめ|AI検索で選ばれる企業になる方法
- 鹿児島でLLMO対策業者を探す前に知っておきたい選び方と依頼のポイント
- 滋賀県のLLMO対策業者おすすめ|AI検索で選ばれる企業になる方法